Appearance
特征工程 / 机器学习 / 普通建模
此场景需要使用的应用: 可视化开发, 数据调度
通过以下 2 步构建机器学习工程
创建 Pipeline, 运行、打包、发布
可视化开发 - Pipeline 设计
创建 Pipeline 工程
普通工程
- 点击我的工程 -
+号新建工程- 工程类型
- 普通: 用于管理普通 Pipeline, 画布中仅可使用普通算子
- 工程类型
- 以下案例创建
普通工程 - Example 工程
机器学习工程
- 点击我的工程 -
+号新建工程- 工程类型
- 机器学习: 用于管理普通 Pipeline, 画布中可使用普通算子和机器学习算子
- 工程类型
- 以下案例创建
机器学习工程 - MLExample 工程 
创建机器学习 - 训练 Pipeline
此案例将创建使用逻辑回归分类算法训练模型的 Pipeline
- 点击工程
MLExample-新增 Pipeline- 引擎类型: 目前仅 Spark 支持机器学习算子, Flink 仅支持普通算子
- 主函数 Class: 程序执行入口类名称
- Pipeline 类型
- 训练
- 模型保存路径: 设置训练的模型文件保存的 HDFS 路径
- 评估参数保存路径: 设置模型评估的结果文件保存的 HDFS 路径
- 训练
- 点击
数据源- 点击批处理数据源- 拖动Libsvm 文件批处理数据源至画布中- 点击参数右侧
?查看参数说明, 按照说明填写 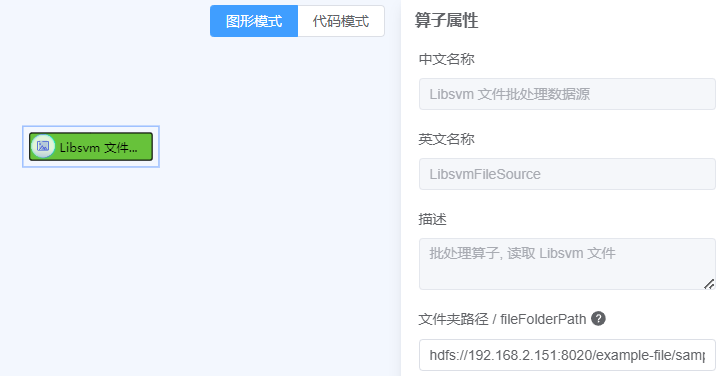
- 点击参数右侧
- 点击
估计器- 点击分类算法- 拖动逻辑回归分类至画布中- 点击参数右侧
?查看参数说明, 按照说明填写 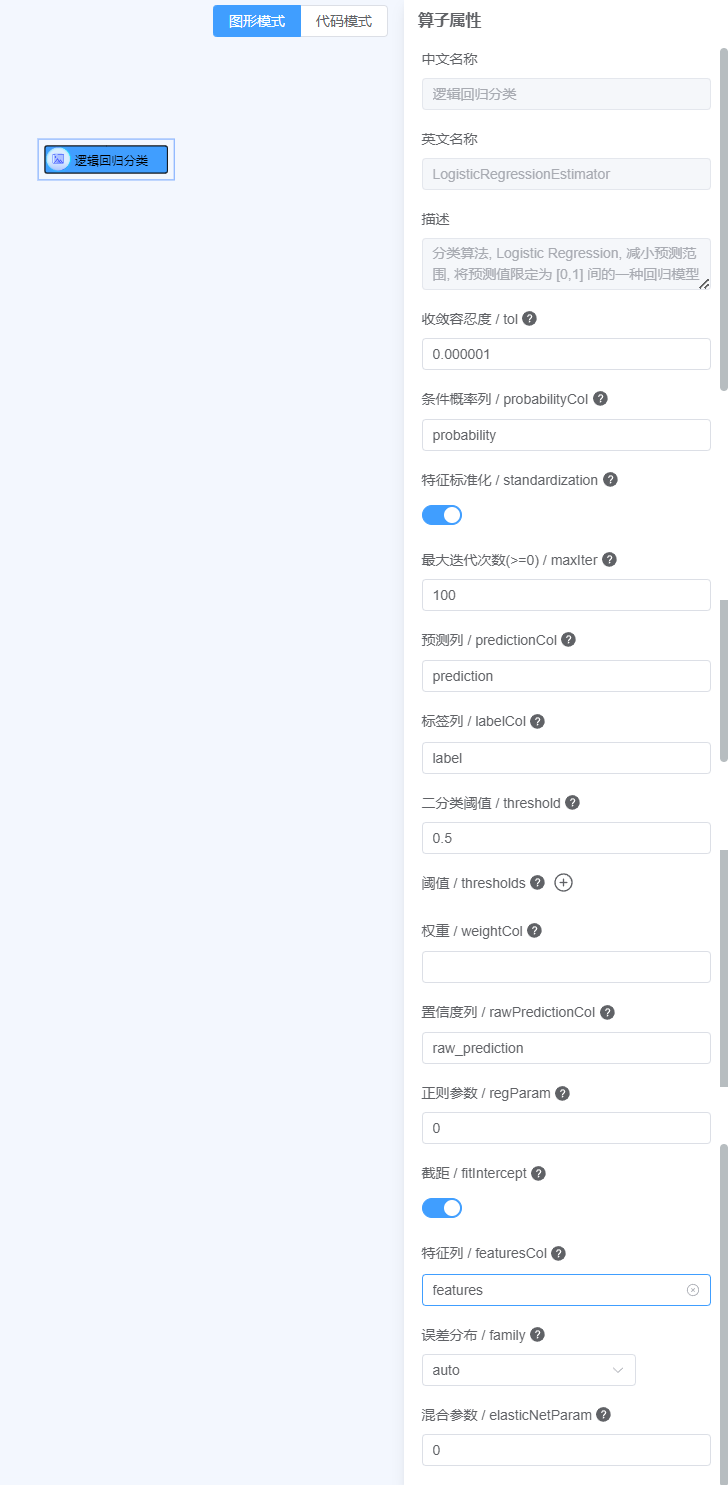
- 点击参数右侧
- 点击
评估器- 点击回归评估器- 拖动回归评估至画布中- 点击参数右侧
?查看参数说明, 按照说明填写 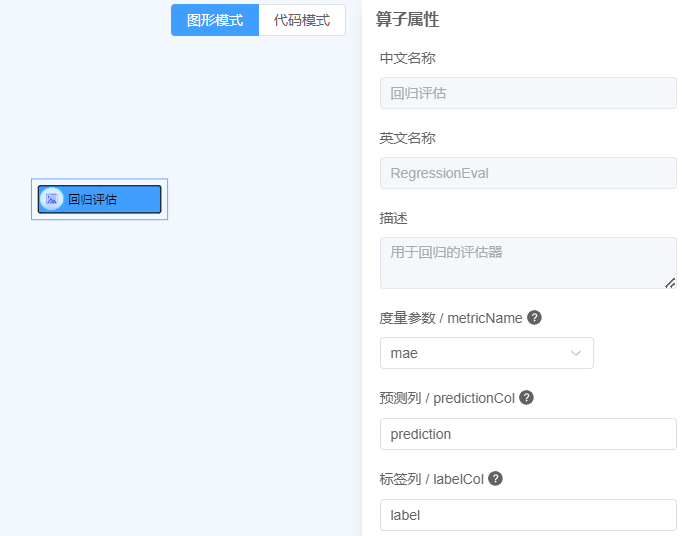
- 点击参数右侧
- 将
Libsvm 文件批处理数据源->逻辑回归分类->回归评估用箭头依次连接起来, 此时一个简单的机器学习训练 Pipeline 设计完成 - 运行测试, 点击右上角
运行- 开始运行: 在线运行测试程序是否正常运行
- 点击
开始运行, 运行结束后将打印日志
- 点击
- 跳过测试: 跳过测试步骤, 即默认程序正常
- 开始运行: 在线运行测试程序是否正常运行
- 代码打包, 点击
下一步- 点击
打包 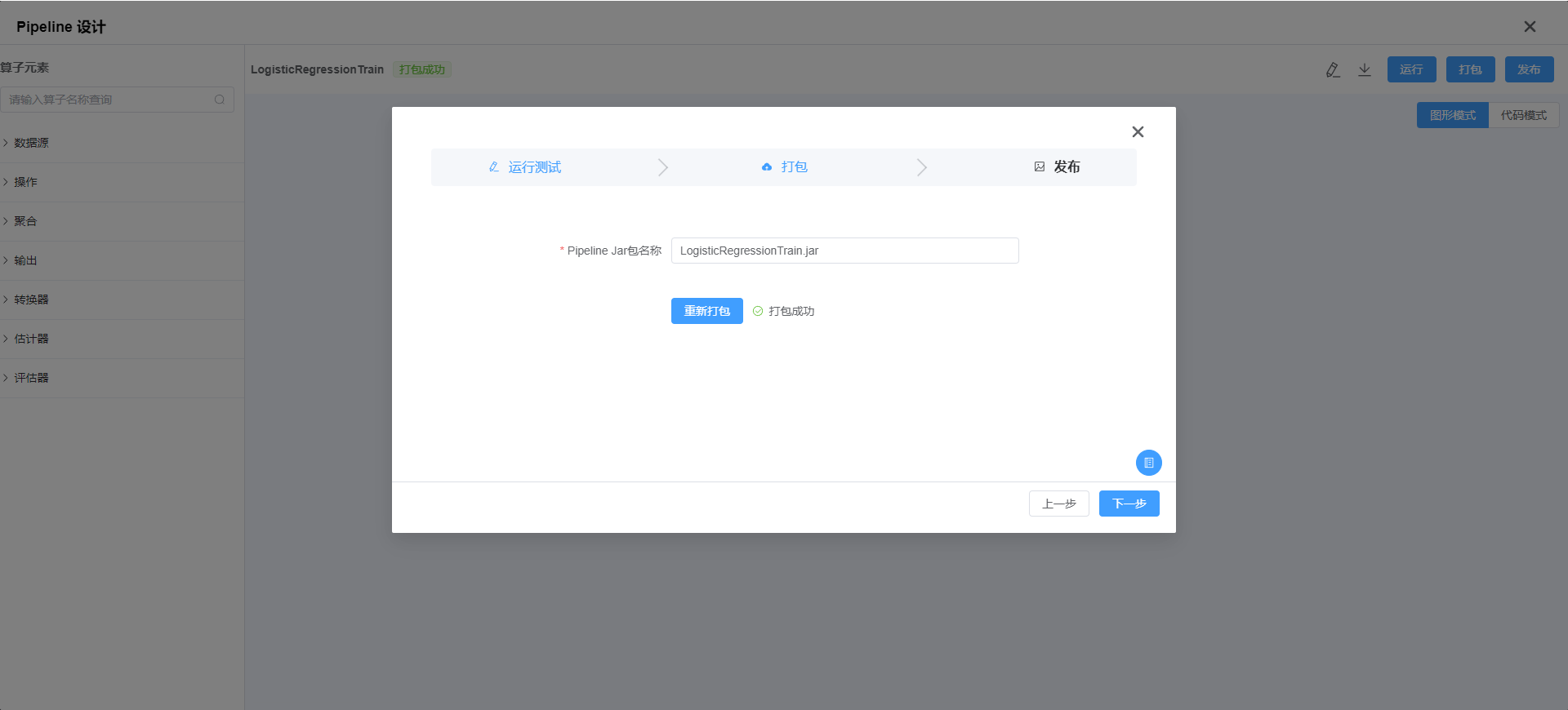
- 点击
- Jar 包发布, 点击
下一步- 选择
文件路径:- 首次使用未创建
文件路径, 请点击去创建跳转数据调度 - 资源中心 -创建文件夹 - example - 回到可视化开发 - 发布页面中点击
刷新按钮, 选择文件路径 - example
- 首次使用未创建
- 点击
确认发布到应用数据调度 的文件路径 - example下
- 选择
创建机器学习 - 预测 Pipeline
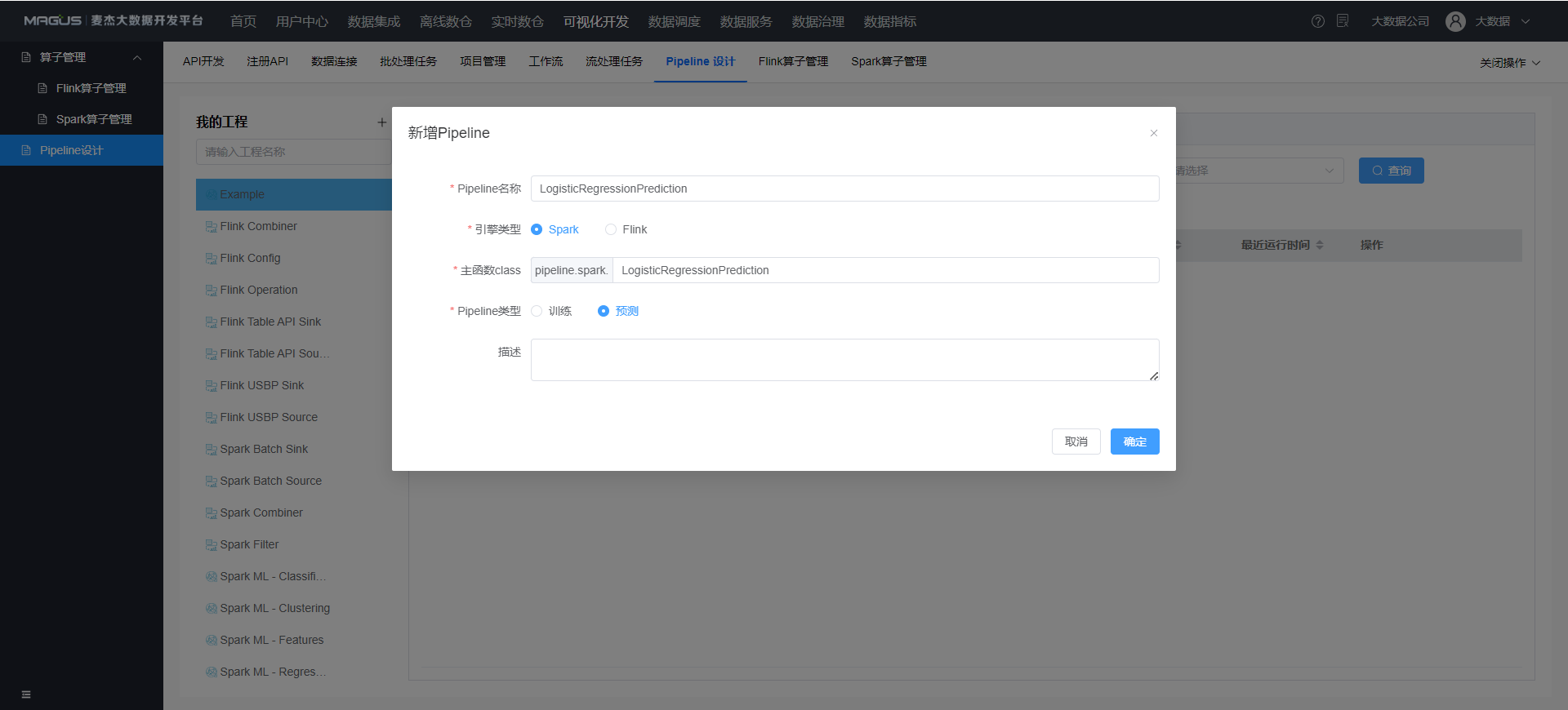
点击工程MLExample - 新增 Pipeline
- 引擎类型: 目前仅 Spark 支持机器学习算子, Flink 仅支持普通算子
- 主函数 Class: 程序执行入口类名称
- Pipeline 类型
- 预测
- 点击
数据源- 点击批处理数据源- 拖动Libsvm 文件批处理数据源至画布中- 点击参数右侧
?查看参数说明, 按照说明填写
- 点击参数右侧
- 点击
操作- 点击模型- 拖动模型加载至画布中- 点击参数右侧
?查看参数说明, 按照说明填写 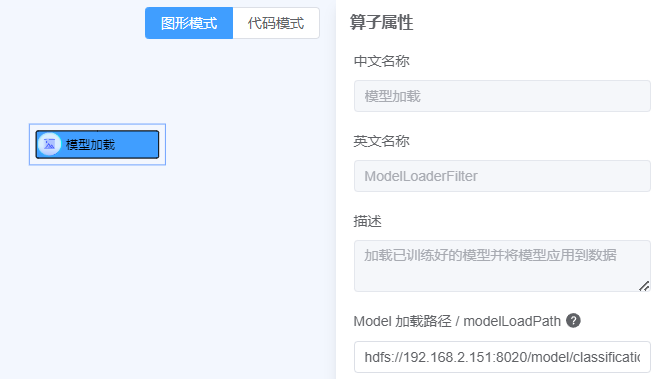
- 点击参数右侧
- 点击
操作- 点击修改- 拖动所有指定字段类型列修改至画布中- 点击参数右侧
?查看参数说明, 按照说明填写 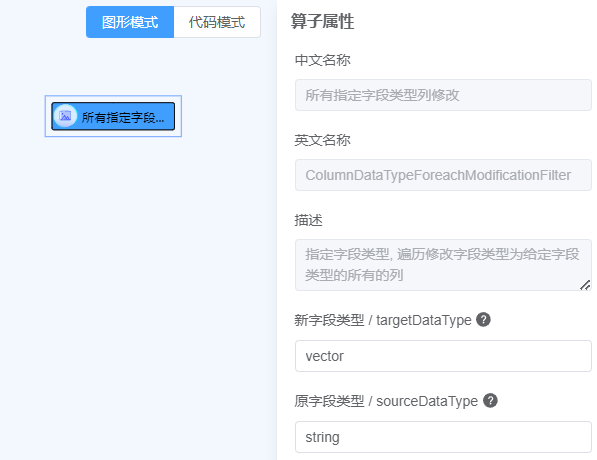
- 点击参数右侧
- 点击
输出- 点击批处理输出- 拖动批处理控制台打印至画布中- 点击参数右侧
?查看参数说明, 按照说明填写 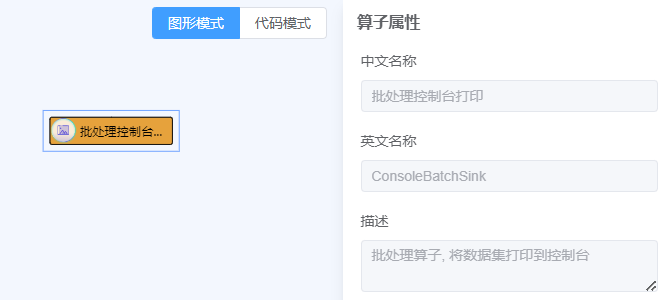
- 点击参数右侧
- 将
Libsvm 文件批处理数据源->模型加载->所有指定字段类型列修改->批处理控制台打印用箭头依次连接起来, 此时一个简单的机器学习预测 Pipeline 设计完成 - 运行测试, 点击右上角
运行- 开始运行: 在线运行测试程序是否正常运行
- 点击
开始运行, 运行结束后将打印日志
- 点击
- 跳过测试: 跳过测试步骤, 即默认程序正常
- 开始运行: 在线运行测试程序是否正常运行
- 代码打包, 点击
下一步- 点击
打包
- 点击
- Jar 包发布, 点击
下一步- 选择
文件路径:- 首次使用未创建
文件路径, 请点击去创建跳转数据调度 - 资源中心 -创建文件夹 - example - 回到可视化开发 - 发布页面中点击
刷新按钮, 选择文件路径 - example
- 首次使用未创建
- 点击
确认发布到应用数据调度 的文件路径 - example下
- 选择
创建普通 Pipeline
- 点击工程
Example-新增 Pipeline- 引擎类型: Spark, Flink, 本案例使用 Spark 引擎
- 主函数 Class: 程序执行入口类名称
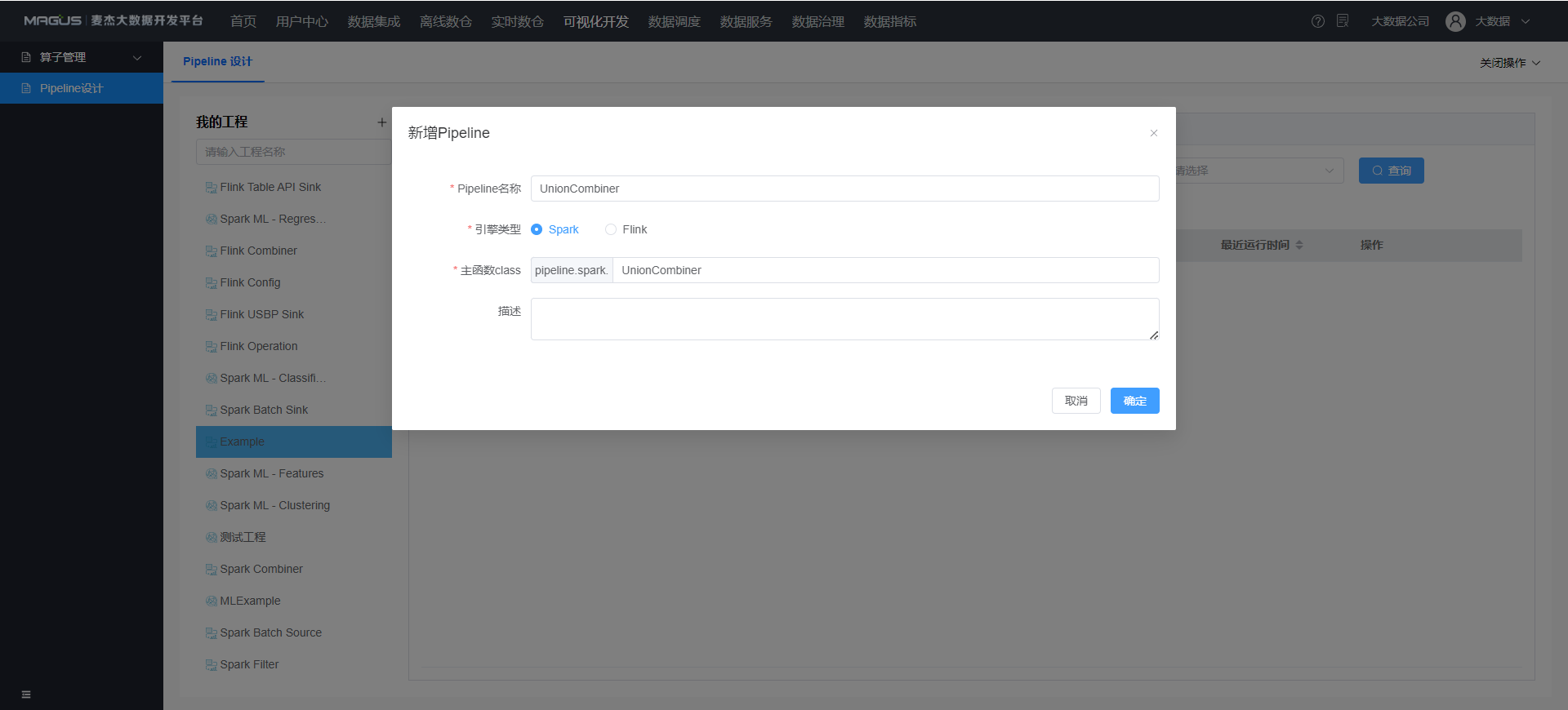
- 点击
数据源- 点击批处理数据源- 拖动JDBC 批处理数据源至画布中- 点击参数右侧
?查看参数说明, 按照说明填写
- 点击参数右侧
- 点击
数据源- 点击批处理数据源- 拖动Doris 批处理数据源至画布中- 点击参数右侧
?查看参数说明, 按照说明填写
- 点击参数右侧
- 点击
聚合- 点击DSL 聚合- 拖动Union 聚合至画布中- 点击参数右侧
?查看参数说明, 按照说明填写
- 点击参数右侧
- 点击
操作- 点击修改- 拖动重复行去重至画布中- 点击参数右侧
?查看参数说明, 按照说明填写
- 点击参数右侧
- 点击
输出- 点击批处理输出- 拖动批处理控制台打印至画布中- 点击参数右侧
?查看参数说明, 按照说明填写
- 点击参数右侧
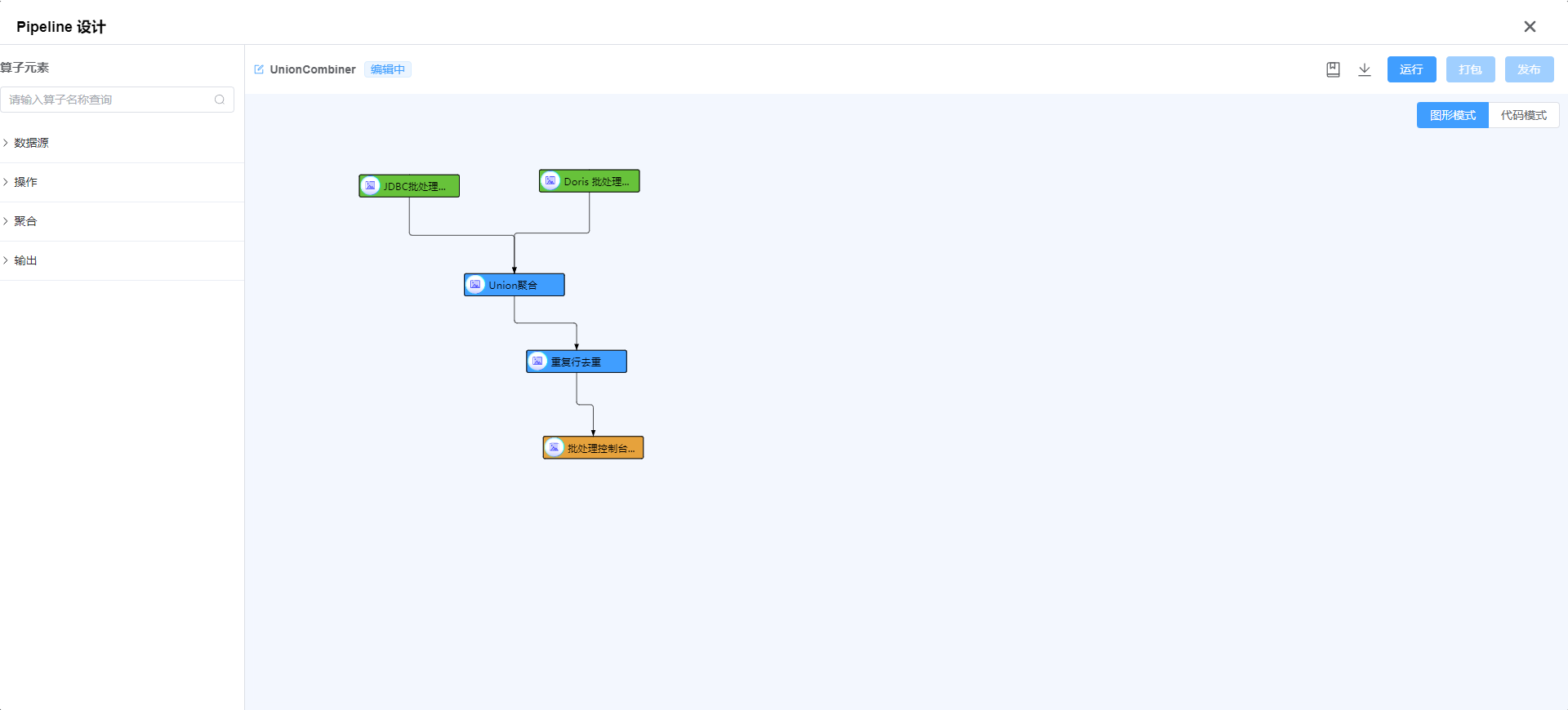
- 将画布中的节点按下图用箭头依次连接起来, 此时一个简单的普通 Pipeline 设计完成
- 运行测试, 点击右上角
运行- 开始运行: 在线运行测试程序是否正常运行
- 点击
开始运行, 运行结束后将打印日志
- 点击
- 跳过测试: 跳过测试步骤, 即默认程序正常
- 开始运行: 在线运行测试程序是否正常运行
- 代码打包, 点击
下一步- 点击
打包
- 点击
- Jar 包发布, 点击
下一步- 选择
文件路径:- 首次使用未创建
文件路径, 请点击去创建跳转数据调度 - 资源中心 -创建文件夹 - example - 回到可视化开发 - 发布页面中点击
刷新按钮, 选择文件路径 - example
- 首次使用未创建
- 点击
确认发布到应用数据调度 的文件路径 - example下
- 选择
创建调度工作流
通过数据调度应用创建调度工作流运行 Pipeline, 以机器学习训练 Pipeline - LogisticRegressionTrain 为例
- 数据调度 - 项目管理 -
创建项目- 首次使用需创建项目, 数据调度中的工作流是以项目为维度管理的
- 创建项目
可视化开发 Example
- 点击项目
可视化开发 Example-创建工作流- 左侧列表选择
Spark类型任务节点拖拽至画布中 - 节点名称命名为
LogisticRegressionTrain - 运行标志: 默认正常
- 任务优先级: 默认 MEDIUM
- Worker 分组: 默认 default
- 程序类型: SCALA
- Spark 版本: Spark2
- 主函数 Class: 填写刚才命名的程序执行入口类全称
- 主程序包: 选择
example/LogisticRegressionTrain.jar - 部署方式: cluster
- 其他参数默认即可
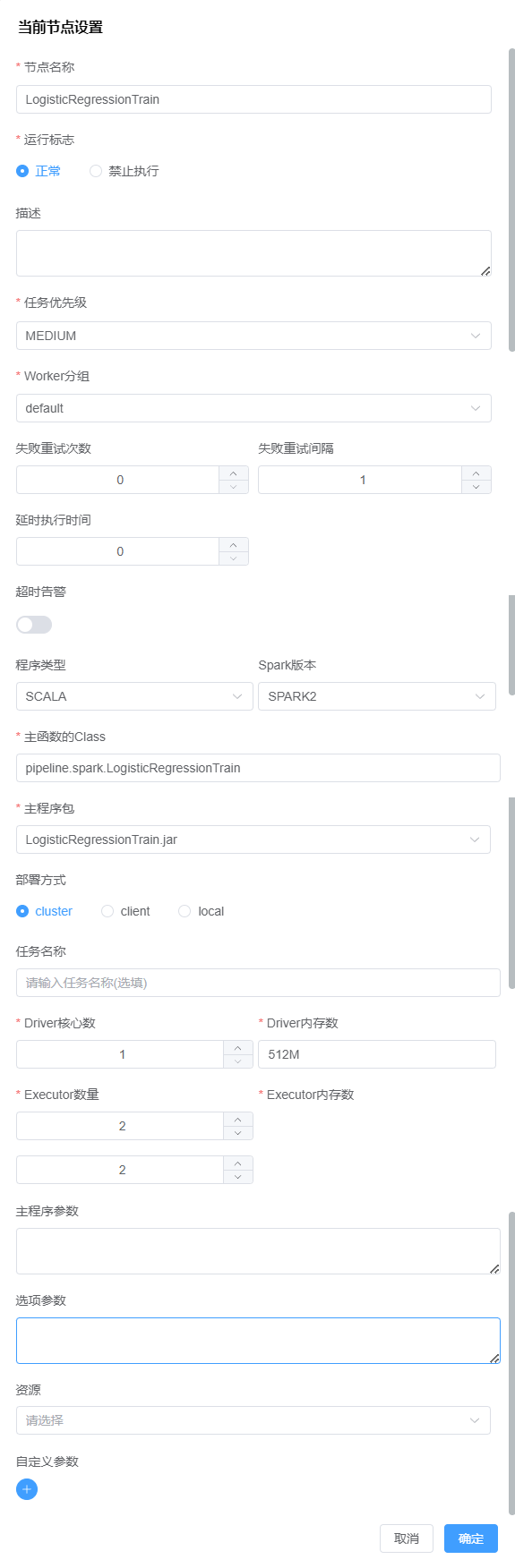
- 保存工作流命名为
pipeline_example
- 左侧列表选择
- 回到
可视化开发 Example项目内, 找到工作流pipeline_example- 测试运行: 点击
上线, 点击运行即可立即运行测试 - 定时调度: 点击
上线, 点击右侧定时按钮使用 CORN 设置工作流执行周期, 并且点击定时管理再点击上线定时, 工作流则会定时执行
- 测试运行: 点击