Appearance
主要特性
数据类型
Lightning System 数据库中数据类型支持:
常见数据类型
bool、int8、int16、int32、int64、float、double、stirng、binary、datatime
高级数据类型支持
Fix Array: : bool/int8/int16/int32/int64/float32/float64/datatime Array 的优化存储结构。
Var Array: String Array, Binary Array。
数据类型
| # | 类型 | Bytes | 说明 | 取值范围 |
|---|---|---|---|---|
| 1 | VtBool/bool/boolean | 1 | 布尔型 | |
| 2 | VtInt8/tinyint | 1 | 1 字节整型 | [-128, 127] |
| 3 | VtInt16/smallint | 2 | 2 字节整型 | [-2^15, 2^15-1] |
| 4 | VtInt32/int/integer | 4 | 4 字节整型 | [-2^31, 2^31-1] |
| 5 | VtInt64/bigint | 8 | 8 字节整型 | [-2^63, 2^63-1] |
| 6 | VtFloat32/float | 4 | 单精度浮点数 | [-3.40282e+38, 3.40282e+38], 有效数字位 7 位 |
| 7 | VtFloat64/double | 8 | 双精度浮点数 | [-1.79769e+308, 1.79769e+308],有效数字位 16 位 |
| 8 | VtDateTime/DateTime | 8 | 时间,支持纳秒 | [1970-01-01T00:00:00Z, 2262-04-11T23:47:16854775807Z] |
| 9 | VtString/char/varchar | n | 字符串 | |
| 10 | VtBinary/binary | n | 字节串 | |
| 11 | VtBoolArray/BoolArray | n | 布尔数组 | |
| 12 | VtInt8Array/Int8Array | n | 1 字节整型数组 | |
| 13 | VtInt16Array/Int16Array | n | 2 字节整型数组 | |
| 14 | VtInt32Array/Int32Array | n | 4 字节整型数组 | |
| 15 | VtInt64Array/Int64Array | n | 8 字节整型数组 | |
| 16 | VtFloat32Array/Float32Array/FloatArray | n | 单精度浮点数数组 | |
| 17 | VtFloat64Array/Float64Array/DoubleArray | n | 双精度浮点数数组 | |
| 18 | VtDateTimeArray/DateTimeArray | n | 时间数组 | |
| 19 | VtStringArray/StringArray | n | 字符串数组 | |
| 20 | VtBinaryArray/BinaryArray | n | 字节串数组 |
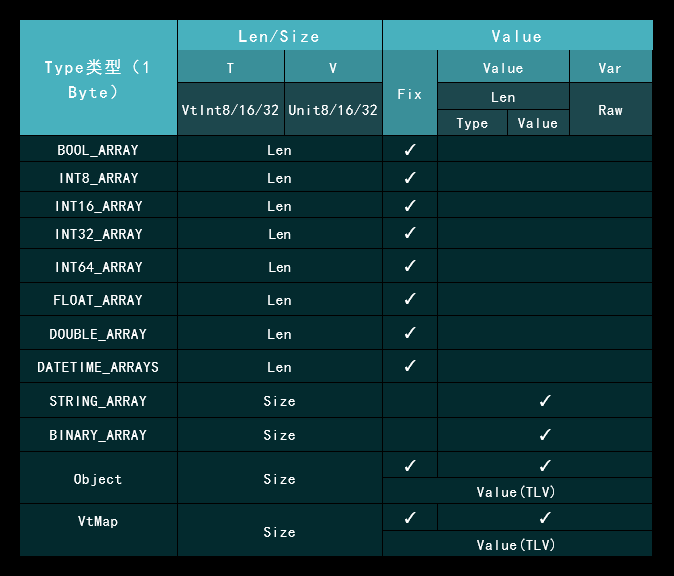
数据描述模型
系统使用 T L V(Type + Len + Value)的模型进行数据结构定义。在保证模型的高空间利用率,低资源占用和高读写性能的同时,提供自解释能力和扩展性。
通过统一的抽象定义(任何数据内容都带有数据类型、长度、数据内容),TLV 形式可以较好的描述二进制数据,数据内容的解释可采用统一标准进行实现。由于数据内容中包含了数据的完整信息,数据在各操作系统、各语言环境下都可以完成对应的语言环境和平台环境的代码实现,满足异构环境的适配。
TLV 结构模型为 Tag (1 Byte) + Length ( Tag + Value) + Value (Binary)

高级类型
版本演进模型
系统数据存储结构中,对其存储的数据内容均定义了数据版本(见数据存储模型 VV)。数据版本字段使用 int32,最大支持变更 21474883647 次。数据库表结构中,所有字段都包含字段索引,索引只进不退,版本演进过程均完整记录。演进示意图如下
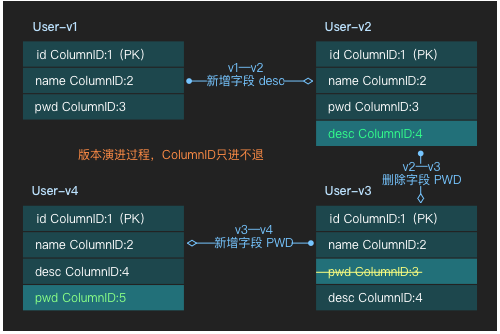
系统提供了版本适配器进行数据结构的应用转换。当前查询、写入动作均以最新版本为基础验证和填充结构即 V4。缺失字段填充规则一律采用默认值填充方式,无默认值情况设置为 Null。
V1-V4 结构转换示意:剔除 index 3,填充缺失字段 index4、index5。
V2-V4 结构转换示意:剔除 index 3,填充缺失字段 index5。
V3-V4 结构转换示意:剔除 index 3,填充缺失字段 index5。
数据版本管理器将各分支版本的数据结构转换,统一格式为最新版本进行计算和对外数据使用。若使用字段要复用之前被删除字段,则需要调用特殊API重建字段 (API 待开放)
事务模型
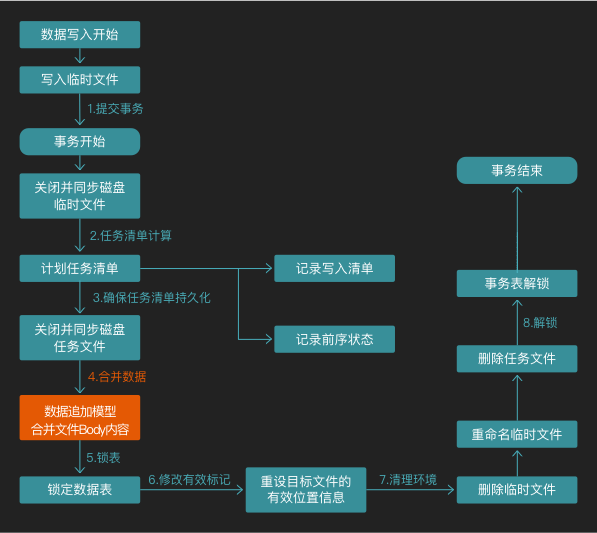
在数据库系统中,事务是不可或缺的一部分。摒弃了传统数据库写入低效的 Binlog 和 Redolog 和 NoSQL 数据库系统的异步的 Sync 方式(失电丢数)。Lightning 采用数据追加机制,在任意任务执行前进行影响预评估,建立 undolog,通过 log 清单 + 异常崩溃修复机制 + 多阶段提交方式,来确保数据可靠落盘入库。做到既保障安全的同时,同时实现快速写入。
SQL 标准
系统以 SQL92 标准为基础,提供经过特定优化的查询子集,完成业务场景构建。秉承与传统数据库(参考 MYSQL)使用方式完全一致概念,建立了流式数据查询模型,其数据操作标准如下:
时间规范
- "2006-01-02", // RFC 3339
- "2006-01-02 15:04", // RFC 3339 with minutes
- "2006-01-02 15:04:05", // RFC 3339 with seconds
- "2006-01-02 15:04:05-07:00", // RFC 3339 with seconds and timezone
- "2006-01-02T15Z0700", // ISO8601 with hour
- "2006-01-02T15:04Z0700", // ISO8601 with minutes
- "2006-01-02T15:04:05Z0700", // ISO8601 with seconds
- "2006-01-02T15:04:05.999999999Z0700", // ISO8601 with nanoseconds
常用的表达式
- 修饰符:+ - / * & | ^ ** % >> <<
- 比较器:> >= < <= == != =~ !~
- 逻辑操作:|| or && and
- 数字常量,作为 64 位浮点(12345.678)
- 字符串常量(引号:“foobar”)
- 日期常量(单引号,使用 rfc339、iso8601、ruby date 或 unix date 的任何排列)
- 布尔常量:true false
- 控制计算顺序()
- 数组(用括号分隔的任何内容:(1,2,'foo'))
- 前缀:!-~
聚合函数
- Max:获取数据列的最大值,针对数值类数据生效。
- Min:获取数据列的最小值,针对数值类数据生效。
- Avg:获取数据列的数学平均值,针对数值类数据生效。
- Sum:获取数据列的数学累计值,针对数值类数据生效。
- Count:获取数据列的总数,针对任意数据列生效。
- First: 获取数据列中时间最早的数据条目,针对任意非时间列生效。
- Last: 获取数据列中时间最晚的数据条目,针对任意非时间列生效。
排序功能
任意系统允许类型进行正逆向排序。采用 TOPK 模型,系统最大排序缓冲区为500 万条,极限返回提供500 万记录的排序结果。排序结果与总数据量无关。排序缓冲区总量可根据业务情况进行配置。
流式查询模型
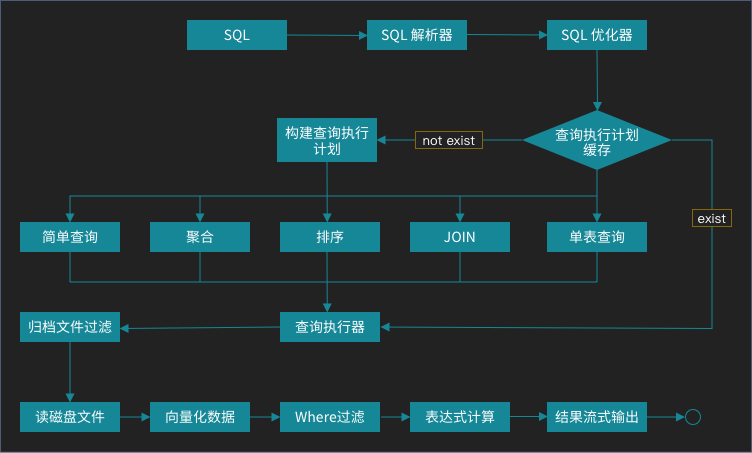
调用者传入 SQL 字符串参数,通过 SQL 解析器 解析为 AST 语法树,然后根据内置表的信息进行 SQL 优化(比如列裁剪,谓词下推,常量折叠等)。
如果 SQL 语句 没有命中执行计划缓存,那么就需要构建执行计划并缓存,再使用执行计划进行 查询执行。
在执行过程中,如果 SQL 语句 中有对时间的过滤,则先将物理文件按时间过滤。再读取磁盘文件内容,将文件内容进行向量化,转为程序可识别的数据结构。
然后进行行过滤,表达式计算,最后将结果流式输出。
插件系统
系统支持自定义跨语言插件,通过配置的方式加载自定义插件,详细配置方式见用户配置:https://doc.magustek.com/Lightning时序数据库/配置说明/用户配置.md
使用自定义插件时,支持使用 Golang 插件方式编译的 .so 插件,也支持 rust 等其他语言编译的 .wasm 插件以及 tinygo 编译的 wasi 插件。
在配置时,需注明插件的类型 (goPlugin, wasm, wasi),路径,函数名称,参数个数及返回值类型,用于做 SQL 预校验。
编译 goPlugin:
go build -buildmode=plugin -o plugin_name.so plugin.gogoPlugin 仅支持 Linux 环境
编译 wasm:
rustc -o plugin_name.wasm plugin.rswasm 方式支持 Windows, Linux, darwin 环境
编译 wasi:
tinygo build --target wasi plugin.go由于 WebAssembly 仍处于实验性阶段,现不支持 string, slice 等等,所以如果要使用 string, slice 作为参数或者返回值,必须采用传 (ptr, size) 的方式。
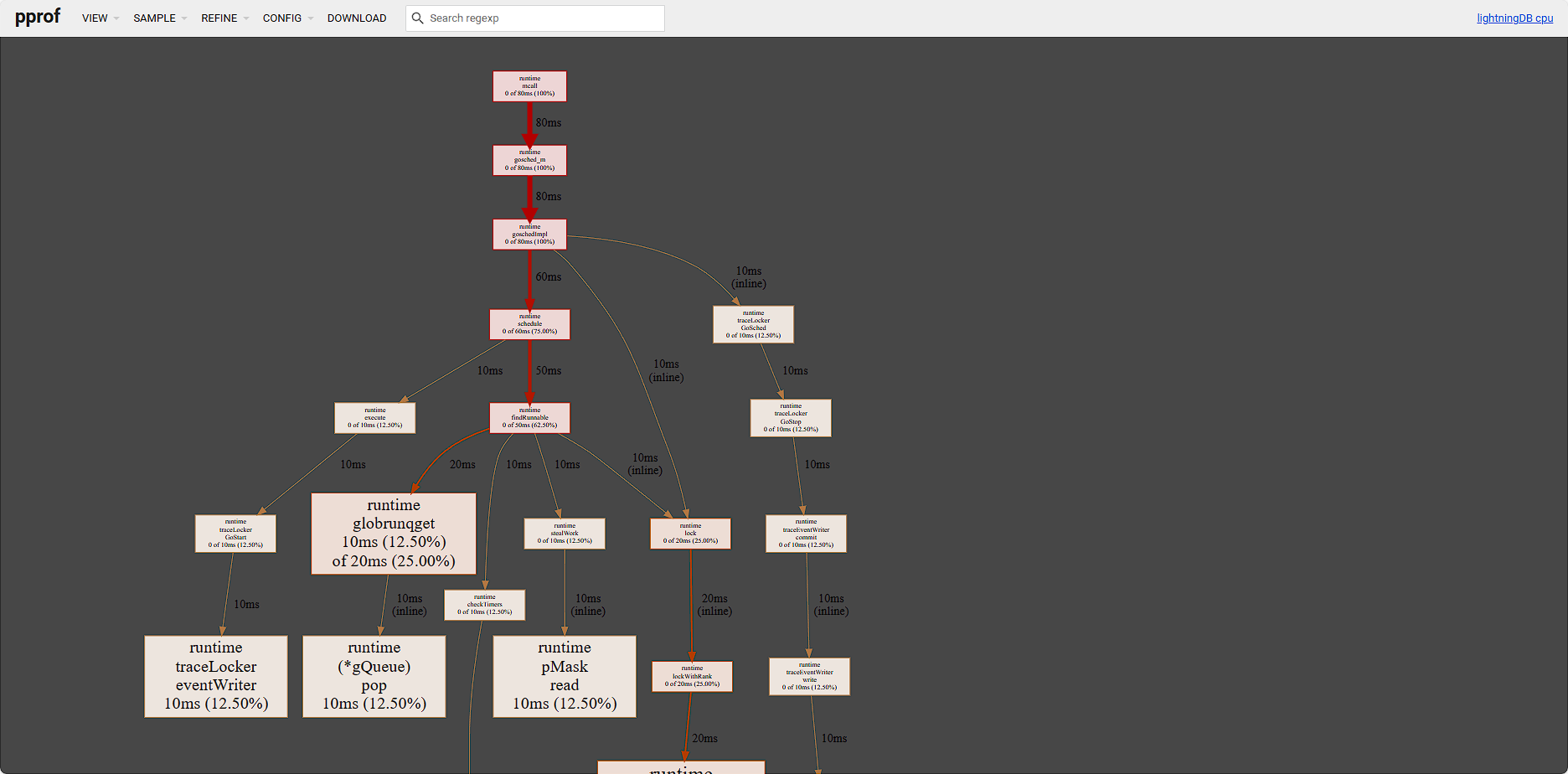
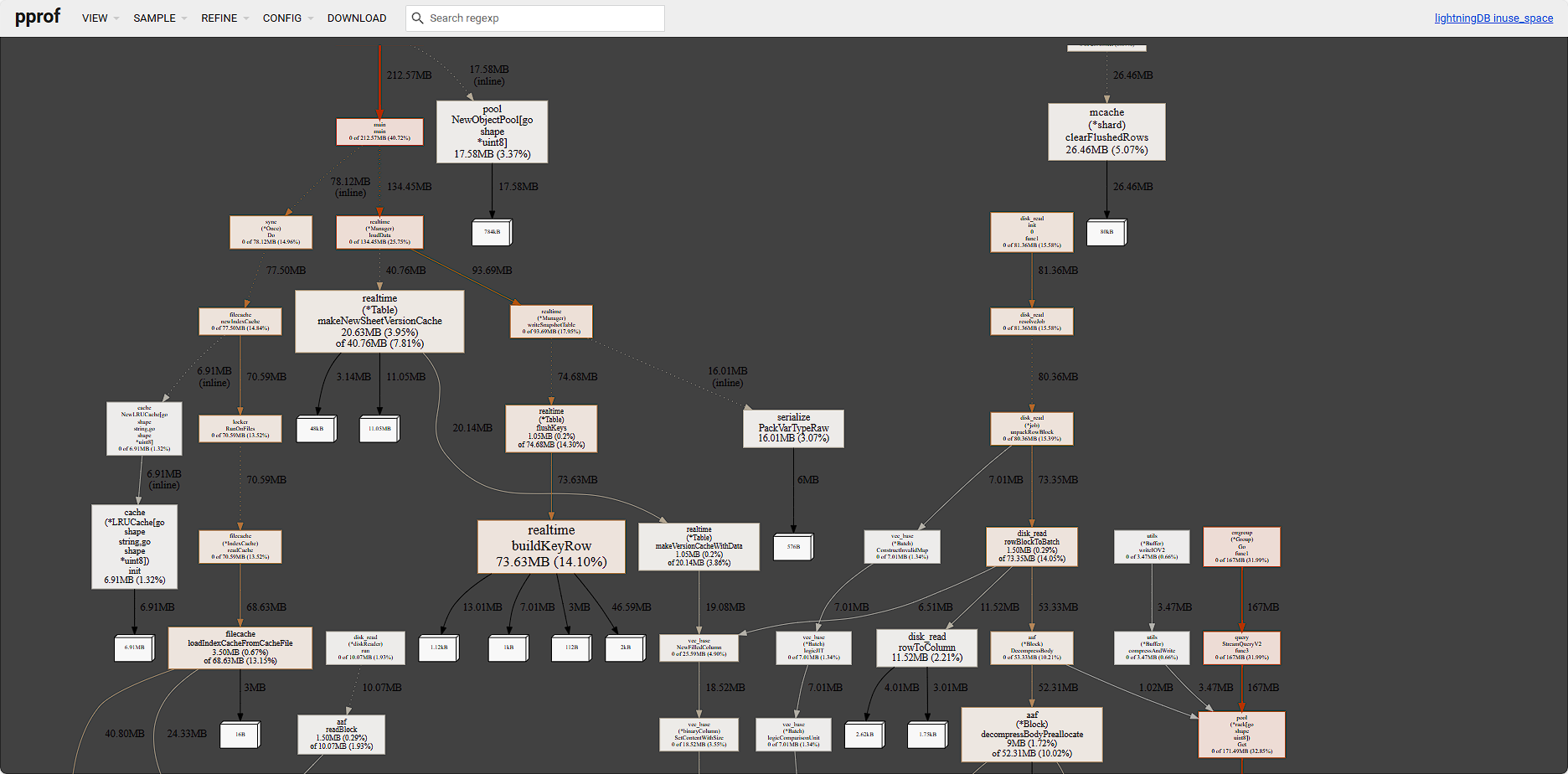
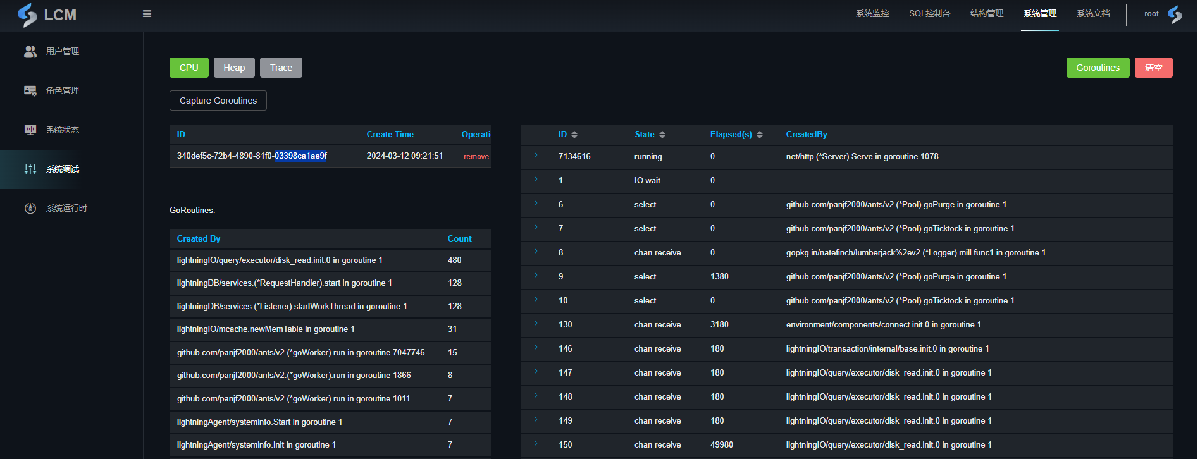
任务追踪
系统开发调试模式下提供了任务跟踪模型,可视图化的方式跟踪任务执行各资源损耗收集,帮助二次数据库开发者快速优化。
通过调试管理控制台可选择系统的 4 种调试服务
- cpu-profile:开启状态下,会记录系统在执行查询语句过程中的服务器 CPU 资源消耗情况
- heap-profile:开启状态下,会记录系统在执行查询语句过程中的服务器内存资源消耗情况
- goroutine: 可获取当前系统的 goroutine stacks,可按 goroutine ID/State/运行时长排序,便于分析系统情况。
系统开启后收集完成的数据记录会自动保存,打开访问连接后即可查询对应的分析视图。